Tri roky UVOstatu - na čom to beží
Posledný diel blogov ku tretiemu výročiu portálu UVOstat bude venovaný tým, ktorých zaujíma, na akej technológii beží celý portál a na aké technické úskalia som po ceste narazil.
1. Back end
Ako som už písal v predchádzajúcich blogoch, pracovným zameraním nie som klasický programátor, ale dátový inžinier. V praxi to vyzerá asi tak, že spracúvam dáta, ktoré dostanem za pomoci všemožných nástrojov, do potrebnej formy na výstupe. Po rokoch skúseností však viem, že najlepšie riešenie na ETL proces (extract -> transform -> load) si skôr napíšem sám, než správne ohnem nejaký korporátny nástroj, ktorý by mi mal uľahčiť robotu. Dlhú dobu to bolo vždy o tom, pripraviť rýchle a hlavne rýchlo vytvorené riešenie, takže som programoval/scriptoval v tom, čo bolo po ruke. Či už to bol Visual Basic a jeho odnože (spomínam si na Cypress Basic, čo bola dosť exotika), Perl, Powershell, alebo Bash, cieľom bolo použiť to, čo už je v korporátnom systéme pripravené a bez nutností ďalších inštalácií som mohol hneď pracovať.
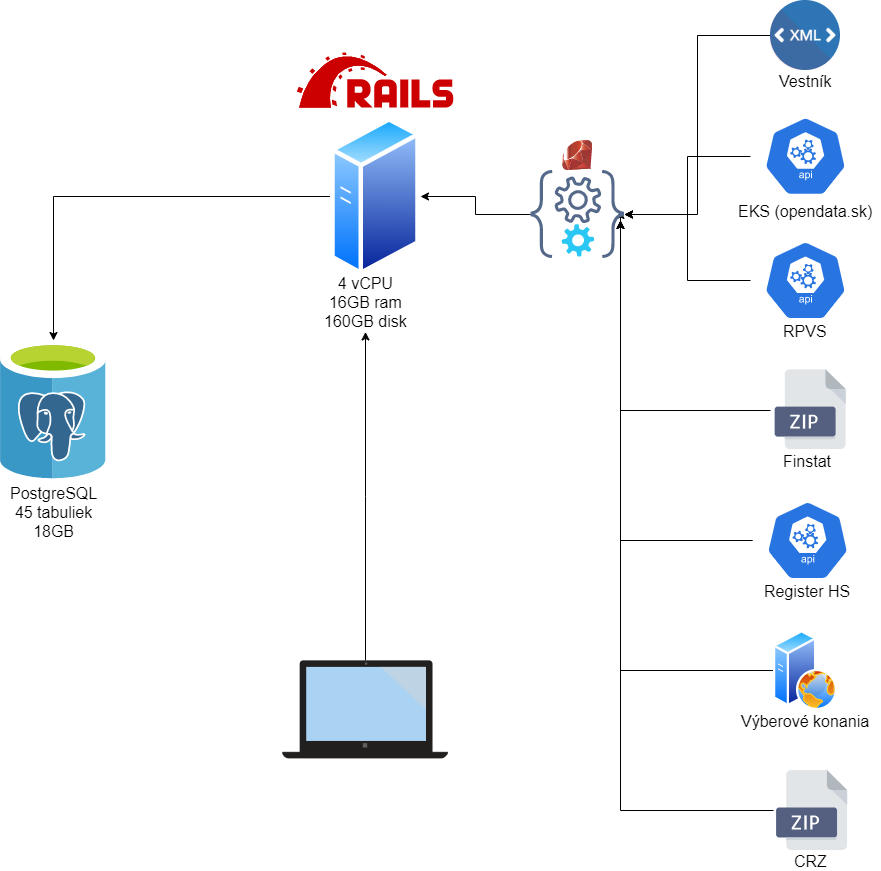
Keď som začal pripravovať prvý ETL proces pre dáta z data.gov.sk, uvedomil som si, že mám konečne plnú voľnosť v rozhodovaní. Pred týmto projektom som robil niekoľko starších webových aplikácií v php (ktorému som sa chcel vyhnúť) a jeden projekt skúšobne v Ruby On Rails (ďalej už len RoR). RoR sa mi ako framework veľmi zapáčil, nie len kvôli rýchlosti vývoja, ale aj vďaka samotnému jazyku Ruby a tak som si povedal, že to celé napíšem v Ruby, čím si uľahčím robotu pri prepájaní dátových procesov na webovú aplikáciu. Doteraz toto rozhodnutie neľutujem a aj keď v práci som postupne presedlal na Python, doma je u mňa vždy číslo jeden pri projektoch.
2. Databáza
Celý Uvostat beží na PostgreSQL, ktorú som si vybral viacmenej náhodou. Pri databázach nemám preferenciu, robím s tým, čo dostanem do ruky. Za tie roky praxe som si prešiel cez MySQL, DB2, MicrosoftSQL, Oracle, Teradata, Sybase, či PostgreSQL, akurát moderným noSQL databázam ako MongoDB sa radšej vyhýbam. Ten hype okolo nich mi nesedí a ešte som nenarazil na také limity klasických relačných databáz, ktoré by ma ich donútili skúsiť. Keď som pripravoval server, na ktorom som bežal vyššie spomenutý prvý projekt v RoR, rozbiehal som celé riešenie u DigitalOcean, ktorí mali predpripravený Ubuntu server s nainštalovaným RoR a PostgreSQL. Ako tvor lenivý som siahol po hotovom riešení a celkom si obľúbil kombináciu RoR + PostgreSQL, preto som toto isté riešenie použil aj na Uvostat.
Keď som asi po roku a pol pripravoval prvé full text prehľadávanie verifikačných dokumentov RPVS, PostgreSQL sa mi osvedčila ako výborne pripravená databáza na rýchle prehľadávanie dlhých textov vďaka dátovému typu tsvector. Aktuálne je v databáze cca 1.2 GB textu z verifikačných dokumentov, čo je veľmi hrubým prepočtom asi milión strán textu a databáza je schopná do sekundy nájsť hľadané slovné spojenie.
3. Server
Prvá verzia Uvostatu bola spustená u DigitalOcean, ktorých som si vybral vďaka predchádzajúcej skúsenosti. Vtedy to bol server s 2 vCPU, 2GB ram a 20GB disk, na ktorom bežalo Ubuntu 14 a ruby 2.1 . Dlhú dobu táto konfigurácia ako tak postačovala avšak práve pri vyššie spomínanom riešení full text prehľadávania verifikačných dokumentov som narazil na prvé komplikácie. Počas prípravy riešenia, ktoré som použil na strojové spracovanie textu z PDF súborov do databázy (Tesseract), som zistil, že musím upgradnúť verziu Ruby (predsa len už som fungoval na dosť starej verzii), pretože som narazil na bug, ktorý bol opravený v novších verziách. DigitalOcean na predpripravenom serveri použil RVM (ruby version management) tool, zatiaľ čo doma používam RBENV (oproti RVM mi príde oveľa jednoduchší a príjemnejší na spravovanie verzií Ruby) na inštaláciu Ruby do Linuxu, plus pomer cena/výkon mi už tak veľmi nevyhovoval, tak som sa rozhodol pre veľkú zmenu. Na celkový upgrade servera som sa odhodlával už dlhšie a tento problém bol posledný klinec do rakvy menom DigitalOcean. Po dlhšom hľadaní som objavil poskytovateľa Hetzner, kde som postavil výkonnejší server (4 vCPU, 16GB ram a 160GB disk) s menšími nákladmi na prevádzku a prevádzkujem tam Uvostat doteraz.
4. Front end
Keďže som fanúšik KISS princípu (keep it simple stupid), veľmi som pri tvorbe užívateľského prostredia nevymýšľal a rovno som vyhodil z hlavy myšlienku použiť Angular, či iný frontend javascript framework a ostal som pri čistom javascripte, resp. ešte stále dosť obľúbenej knižnici jQuery. Vďaka Turbolinks, chválenej, ale často aj nenávidenej funkcii RoR, vie aplikácia postavená na tomto frameworku ponúknuť dojem podobný ako SPA (single page application) tým, že pri kliknutí na link miesto opätovného načítania všetkých javascript/css súborov asynchrónne načíta žiadaný obsah a len ten prekreslí. Sám som pri práci na portáli strávil niekoľko naštvaných nocí, keď som zisťoval, prečo mi kvôli turbolinks robí javascript rôzne psie kusy ako duplikovanie elementov, či nespúštanie scriptu vtedy, keď som ho očakával.
5. Niekoľko čísel
Ako som už vyššie spomínal, aktuálne beží Uvostat na serveri v konfigurácii 4 vCPU, 16GB ram a 160GB disk s Ubuntu 18.04. V databáze je 45 produkčných tabuliek o veľkosti 18 GB, z ktorých väčšinu zaberajú strojovo spracované dokumenty verejných obstarávaní (aktuálne niekoľko miliónov strán textu). Denne beží na pozadí 16 procesov (plus ďalšie 4 raz za týždeň), ktoré spracúvajú dáta zo sedem rôznych dátových zdrojov (detailne o spracovaní všetkých dát môžem spísať v extra blogu ak by bol záujem).
V aplikácii je zdokumentovaných vyše 100 000 nákupov štátnych inštitúcií, ktoré išli cez vestník, alebo elektronické trhovisko.
6. Plány do budúcna
V predchádzajúcich blogoch som spomínal, že sa už dlhšie odhodlávam na upgrade RoR na novšiu verziu. S týmto upgradom mám taktiež plán postaviť nový testovací server, kde by som bežal paralelne skúšobnú verziu portálu, keďže aktuálne ešte stále fungujem pankáčskym prístupom a veľa vecí po otestovaní u seba doma rovno nahodím do produkcie.
Z dátového pohľadu aktuálne pripravujem zber dát o novo vyhlásených obstarávaniach vo vestníku, kde budem ponúkať podobnú funkciu notifikácii ako u výberových konaní. Po diskusii s ľuďmi na UVO taktiež pripravujem spracovanie dokumentov ako sú rozhodnutia o námietkach, uložených pokutách, odvolaniach a iné, v ktorých chcem pripraviť pokročilé vyhľadávanie a zároveň automatickú klasifikáciu pomocou strojového učenia (machine learning).
Taktiež by som rád rozbehal Redis ako cache a pokúsil sa zlepšiť "User experience" lepšou odozvou. V rámci nástrojov pre používateľov, ktorých zaujímajú detailnejšie štatistiky, chcem nainštalovať Metabase, čím si uľahčím prácu, keďže aktuálne dostupná funkcia detailného reportu nie je zrovna to pravé orechové.
V prípade, že ste nečítali prvé dva blogy, kde opisujem prvé tri roky portálu Uvostat, môžte si ich prečítať tu:
Tri roky UVOstatu - prečo a ako vznikol
Tri roky UVOstatu - prevádzka, nápady, spolupráce
Ak sa vám myšlienka portálu uvostat.sk páči, môžete ju podporiť pravidelným príspevkom cez portál Patreon, jednorázovo podporiť cez PayPal, alebo zahlasovať za článok na vybrali.sme.sk. Taktiež môžete sledovať UVOstat na facebooku, kde sa dozviete vždy všetko nové.


